nemo 🐦 🦣 🐳 🃏
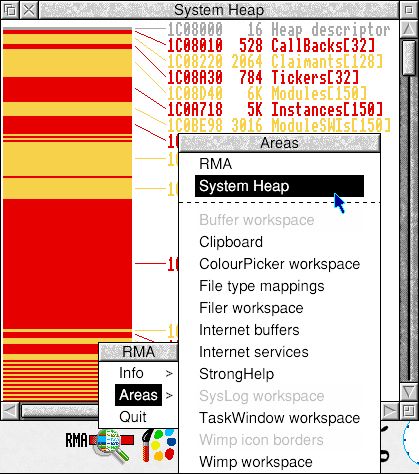
A RISC OS memory management deep-dive thread. The RMA is a chaotic pile of allocations of wildly differing sizes – not just “node soup” but minestrone. But it’s not the only heaped area in RO – the Kernel uses the System Heap for similar purposes, but was intended to use a less chaotic strategy.
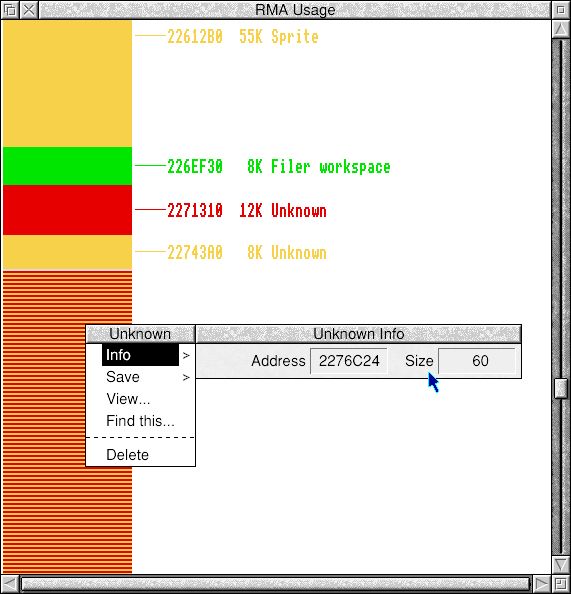
The main problem with using a Heap for large numbers of small allocations is the granularity of the allocation unit – 8 bytes in general, but 16 bytes for the RMA. Since each allocation has a header, that means “8 byte” heap allocations use 16 bytes; every “16 byte” RMA allocation actually takes 32.
So the Kernel groups same sized-allocations into groups – like a Chocolate Bar made of identically-sized Pieces. This technique, usually called Memory Pooling, reduces wastage and fragmentation, and can include strategies for dealing with the highly variable number of allocations you get in a PC.
Sadly the RO Kernel isn’t very clever about this. Firstly it DOESN’T group same-sized Pieces but same-purpose ones. This adds wastage due to duplication and doesn’t even protect against threading issues (as IRQs are always off when mutating them). But a worse problem is the Bars themselves...
Not only are they fixed-size and cannot expand when full, they can’t even be chained together to allow more allocations... So once a Bar is full, every further allocation is just a standard Heap allocation, with all the alignment bloat, admin overhead and resulting node-soup that implies.
So those singleton fixed-size Bars had better be a sensible size, yeah? Go on, guess, RISC OS survivor. Post-boot, RO5 has about 50 Vector Claimants, so the 128-entry Claimant Bar may seem sensible... but in my version of RO4 there’s 121 vector Claimants before I’ve started doing anything!
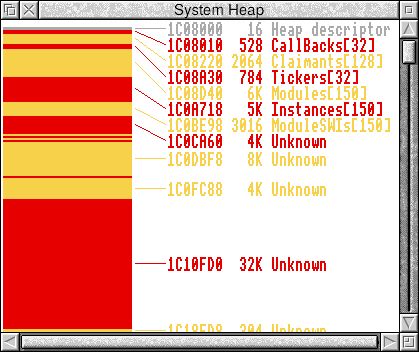
The Module and Instance bars have 150 slots each, which RO5’s 125 modules are already near monopolising, but my OS has more than 250 modules by the time the Desktop appears! Meanwhile, the CallBacks bar has 32 slots... but spends almost all its time empty of course.
It has to be said, the System Heap is mostly SysVars and AMB page tables, which are highly variable-sized of course, but this form of Memory Pooling was introduced in 1998 in RO 3.80 (which had 120 modules in its ROM) but those sizes HAVEN’T CHANGED SINCE! (RO 4.39 has 165 modules, 6.20 has 211!)
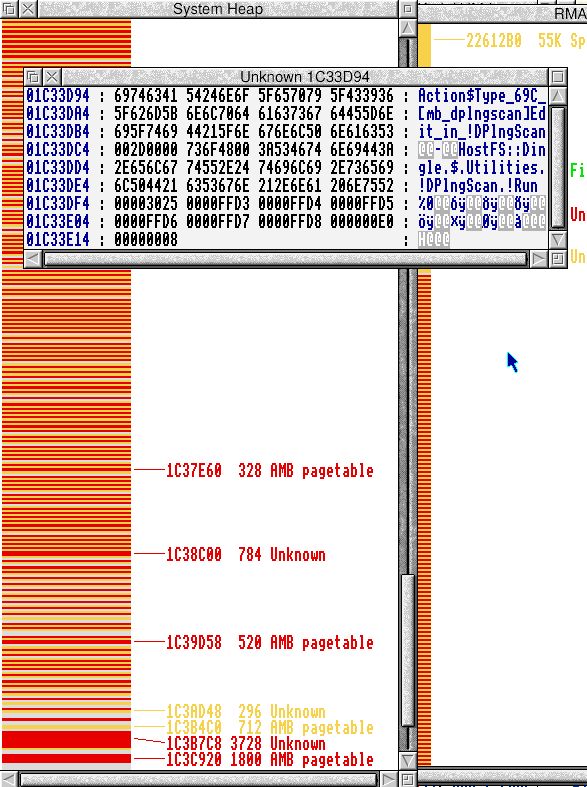
Fortunately it’s not the multiplicity of allocations that slows down Heap management, but the number of free blocks – every time an allocation of free takes place, a chain of freed blocks must be traversed (and in the case of free, this can cause up to three blocks to be merged).
Memory pooling removes that overhead – it doesn’t matter how many frees you have in the pool because they’re all the same size and they can only be used for that size allocation, so you can just use the first one you find rather than looking for the best match.
So this oversight is wasteful, slow, and due to all the overflow exposing crucial system allocations to neighbouring unrelated blocks on all sides, potentially more fragile. [I’m particularly uncomfortable about SysVar blocks, as pointers to those allocations are returned from ReadVarVal]
I’m currently reworking my vector code, so I’m thinking of improving the Kernel’s use of memory pooling in the System Heap. In an ideal world SysVars would pool too, and all the various pools in the System Heap could have a compatible size, eliminating fragmentation. Anyway. Fixed-size arrays=dumb.

BTW, whereas my RMA right now has 20 freed blocks, my System Heap has over 150. So fragmentation is a much worse problem for the System Heap than the Module Area. Bear in mind this OS is based on 4.39, which spins much RMA soup into their own DAs, so that helps a lot. Regardless, SysHeap is holey.
Visualisations thanks to an update to !RMA which now supports System Heap everywhere and Heaped Dynamic Areas in modern OSes (ie not you RO5).